April 8, 2026
AI MasterClass
Stop Prompting AI. Start Building it.
The Month AI Broke
There's a new word gaining traction in AI circles: harness.
If you've been around a while, you might map it to "scaffolding," the code you write around a model to make it useful. But harness is the better word, because it implies control.
At its core, a harness is a software framework that reduces unintended behavior of AI agents. It decides what to store, what to retrieve, when to show it to the model, and what to do with the output.An eval harness converts your intent into benchmarks. An evolution harness updates your code in the intended direction. It's everything except the model weights, and as of this month, it might matter more than the weights themselves.
Palantir CTO Shyam Sankar was recently asked what he'd tell his children to focus on in the age of AI. His answer: "Extreme agency. All the other skills, you'll be able to figure out as you go."

It's a powerful line. But March and April 2026 asked the harder follow-up: Agency toward what?
Four stories landed almost simultaneously this month. Individually, they look like unrelated news. Lined up, they tell one story: Stanford proved that AI builds better harnesses than humans, a 6x performance gap on the same model, just by changing the wrapper. Anthropic accidentally leaked the source code of Claude Code, and inside it was a blueprint of what a production-grade harness actually looks like. A North Korean supply chain attack hit the most popular HTTP library on npm, showing what happens when developers ship code they don't understand. And a leaked model called Mythos crashed $15 billion in cybersecurity market cap, because the market realized its defenses were built for a slower era.
The thread connecting all four: the gap between AI capability and human understanding is widening, and most people are building on the wrong side of it.
The era of "vibecoding" is hitting a wall. We're entering the era of Harness Engineering.Here's what that means.
The Shift: Stanford's Meta-Harness
For years, we've obsessed over model weights. Stanford just proved that the weights are only half the story. The harness, the code that decides what information to store, retrieve, and show the model, can produce a 6x performance gap on the same benchmark.
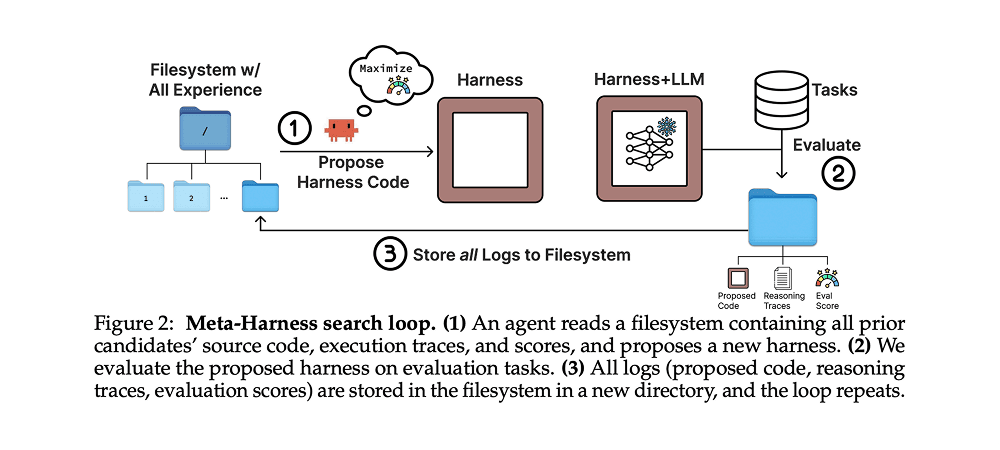
Harness engineering has always been manual and heuristic. But Stanford's Meta-Harness project changed the game by automating it. They built an "outer-loop" system where an AI proposer acts as a detective, reading raw execution traces and failure logs (not just summaries) through a filesystem.
While human-designed optimizers struggle with compressed feedback, Meta-Harness digests up to 10 million tokens of diagnostic data per evaluation. The result? It discovered a specialized "lexical router" for math, applying different retrieval policies for geometry versus number theory, that no human had thought to design. This automated harness outperformed the best hand-engineered systems by 7.7 points while using 4x fewer tokens.
The best wrapper for an AI model is one written by another AI.
The Blueprint: The Claude Code Leak
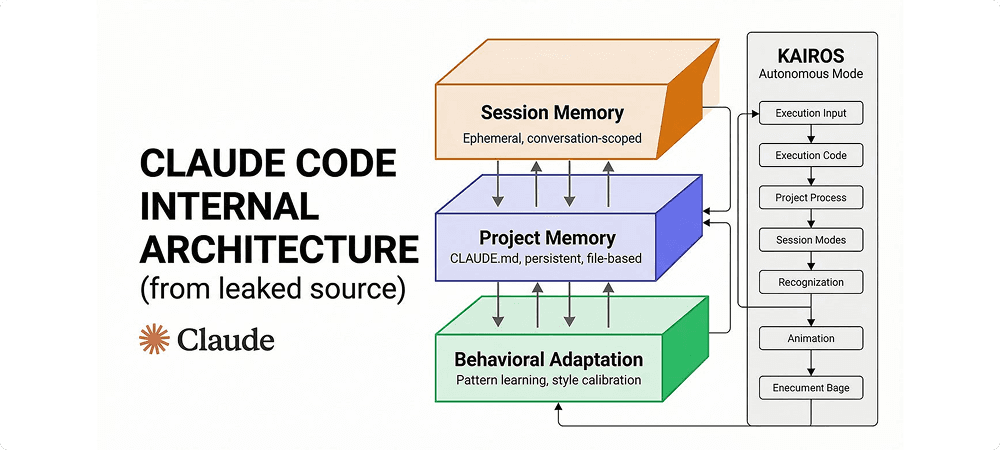
On March 31, Anthropic accidentally shipped the complete source code for Claude Code via an npm source map. 512,000 lines of TypeScript went public, and they revealed that Anthropic is already building exactly what Stanford researched: a production-grade autonomous harness.
Inside the leak, the community found the "North Star" of agentic architecture:
- KAIROS (The Persistent Daemon):An unreleased, always-on agent mode mentioned over 150 times. It doesn't wait for your prompt; it subscribes to GitHub webhooks and Slack messages, acting proactively while you're away.
- autoDream (Memory Consolidation):A background process that triggers when the user is idle. It performs a "reflective pass" over session transcripts to merge observations, remove contradictions, and prune "context entropy."
- Undercover Mode: The leaked code appears to include a stealth system designed to strip AI attribution from public commits, potentially allowing contributors to use an agent without revealing it. The exact scope and intent of this feature remains unconfirmed.
- The Two-Tier Web:The leak exposed a "pre-approved" list of roughly 85 to 107 documentation sites (React, AWS, MDN, etc.) that get full content extraction. Every other site on the internet gets truncated to a 125-character quote.
The leak proved that the product isn't the model anymore. It's the agentic OS wrapping it.
The Infrastructure: TurboQuant
If you want to run an always-on daemon like KAIROS with a million-token context, you hit a brutal wall: Memory. The KV cache(the "digital cheat sheet" of an LLM) is too heavy.
Google DeepMind's TurboQuant (ICLR 2026) just solved this. It compresses KV cache vectors down to 3 bits with zero accuracy loss, delivering an 8x speedup on attention computation.
How? By utilizing a two-stage pipeline — PolarQuant for random rotation of data vectors into a predictable "circular" grid, eliminating the need for expensive per-block scaling factors, and Quantized Johnson-Lindenstrauss (QJL) for 1-bit error correction.
TurboQuant achieves lossless 3-bit compression, reduces memory footprint by at least 6x, and enables an 8x speedup in attention computation. Infrastructure is no longer about "more RAM" — it's about the math required to compress a million-token context into something that can run on a single GPU.
The Consequence: Mythos and the Axios Backdoor
Agency without understanding is just velocity toward a wall. Two events this month proved how high those stakes are:
- Mythos/Capybara:A CMS misconfiguration on Anthropic's website exposed roughly 3,000 internal files, including draft blog posts describing a new model tier called Mythos that sits above Opus entirely. Anthropic's own draft said it "poses unprecedented cybersecurity risks" and "far outpaces defenders" in exploit generation. The news wiped $15 billion in market cap off cybersecurity firms in a single session.
- The Axios Backdoor: While the world was looking at the Claude leak, attackers compromised the axios npm package (100M+ downloads/week). Poisoned versions embedded an obfuscated dropper for the WAVESHAPER.V2 backdoor, stealing cloud keys and API tokens within seconds of installation.
If you are "vibecoding," shipping functional code with an agent without reading the dependencies it pulls in, you are a sitting duck. The Axios attack succeeded because developers stopped auditing the "just npm install it" workflow.
The Bottom Line
Vibecoding ships fast. Harness engineering ships things that last.
The real fast code isn't what you wrote in 10 minutes with a prompt. It's the code that doesn't blow up 10 months later because you actually understood what you were shipping.
Cohort 5 opens in August. Until then, build. Study the Claude Code architecture that's now public. Implement your own memory consolidation logic. Experiment with retrieval routers. But also: read your dependency trees. Audit what your agents install. Understand the harness, don't just use it.
And if you're in Bangalore on May 15th
Join us for AIM Unplugged. No slides, no pitches. Builders in a room talking about what they're actually shipping and what broke along the way.
The tools are moving too fast to figure out alone. Come build community with the people who are actually paying attention.




Until then, keep building. Carefully.